
一个命令行工具,帮你分析你的电脑能跑哪个开源大模型
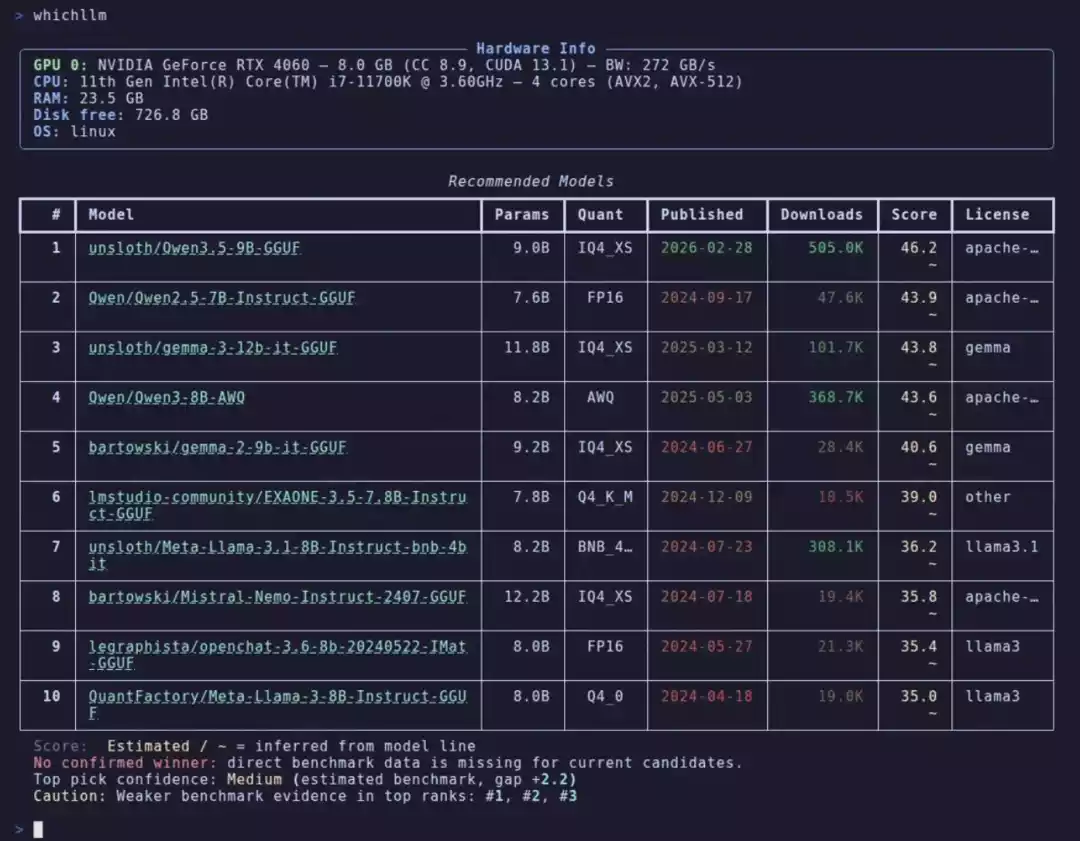
一个命令行工具,解决一个实际问题:你的电脑能跑哪个开源大模型,跑起来效果怎么样。它自动识别你的显卡、CPU、内存,然后从 HuggingFace 上筛选出适配你硬件的模型,按真实跑分排序,不是简单看参数量谁大。
Github地址
https://github.com/Andyyyy64/whichllm
核心功能
- 硬件自动识别:NVIDIA、AMD、苹果芯片、纯CPU都能认,VRAM 怎么算的门清(权重 + KV缓存 + 激活值 + 框架开销)
- 真 benchmark 排序:综合 LiveBench、Artificial Analysis、Aider、Chatbot Arena ELO 等来源,分数标置信度——直接测过的、变体继承的、基座模型推算的、上传者自吹的,权重依次打折。老模型靠旧榜单刷的分会被时间衰减压下去
- 模拟硬件:加
--gpu "RTX 4090"就能假装有这张卡,买之前先算能不能跑你想要的模型 - 一键跑模型:
whichllm run "模型名"自动下依赖、下权重、开聊天,支持 GGUF/AWQ/GPTQ/FP16 格式 - 输出 Python 代码:
whichllm snippet给复制粘贴就能跑的加载代码 - JSON 输出:加
--json进脚本流水线,配合jq用
安装与使用
最快试一把,不用装:
1 | uvx whichllm@latest |
常用就装上:
1 | uv tool install whichllm |
装完直接 whichllm 跑。几个典型用法:
1 | whichllm |
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 马斯克的赛博空间!
相关推荐



评论

